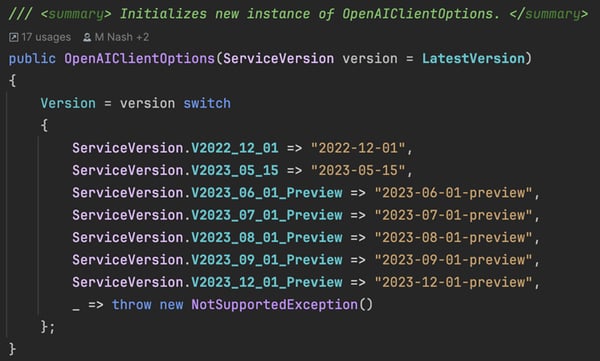
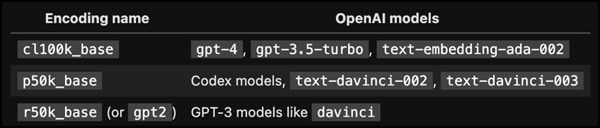
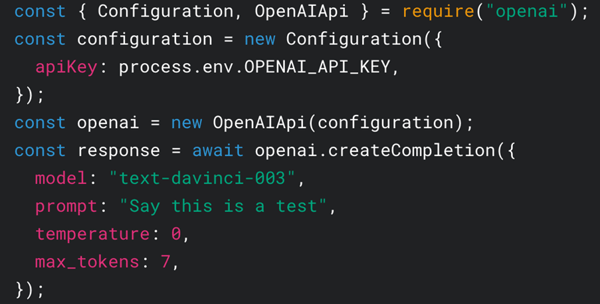
How we are doing RAG AI evaluation in Atlas
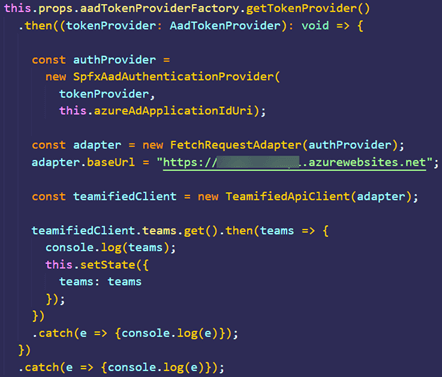
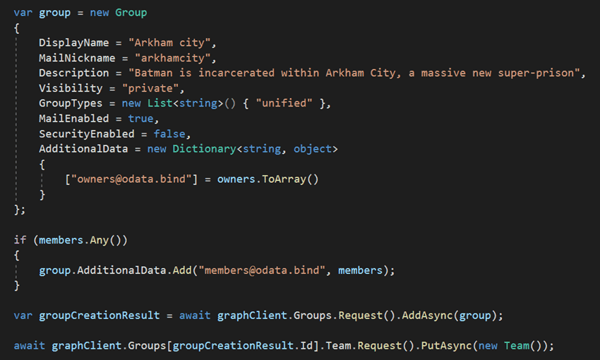
As AI adoption continues to accelerate, organizations are increasingly relying on Large Language Models (LLMs) to power intelligent applications—from chatbots to copilots to knowledge assistants. But building an AI system is just the beginning. One of the most critical, yet often overlooked, aspects of the AI development lifecycle is evaluation: understanding how well your system performs, identifying failure modes, and making informed decisions about models, prompts, and architecture.